Everyone is talking about vectors these days. Cosines, ANN searches, normalizations, sentence embeddings—there’s so much to know, it can feel a bit overwhelming at times!
In the last half year or so, the engineering team at DataStax has been busy delivering a performant, efficient, and scalable vector database experience. Our work spanned many areas, including – crucially – offering guidance to customers and helping them figure out how to get the best out of their vector-based applications.
On this journey (which, as the saying goes, is far from over), we noticed recurring pitfalls, dead ends, and, generally speaking, "things one should've known earlier," on topics ranging from the basics all the way to weird corner cases one does not often think about.
This four-part series of articles is an attempt to collect some of these findings for the benefit of the reader and their future vector-based endeavors. Although these posts are mostly about "mathematical" properties of vectors (which are valid irrespective of the backend you’re using), a few of the remarks will be specific to Apache Cassandra®'s and DataStax Astra DB's stance on vectors.
This first article covers general properties of vectors and tips to interact with them, independent of their origin and purpose. The second article will examine the various notions of vector similarity and their properties. In article three, we’ll take a closer look at the usage of Cassandra and Astra DB with vectors. Finally, we’ll offer a couple of quirks and corner cases to keep in mind in your Cassandra- or Astra DB-enabled vector applications and a small example of a full "migration between vector stores," with an emphasis on the pitfalls with distances and similarities.
The basics
What is a vector?
A vector is a quantity used in geometry and most sciences to denote a phenomenon with a direction and a length (the mathematically rigorous readers, I am sure, will pardon this very practical definition). To describe the blowing of the wind at a given point, for instance, you might use a vector (the vector "length" would be then the wind intensity). With a certain choice of a reference basis (e.g. the x, y and z axes for three-dimensional vectors), a vector can be formulated as a list made of numbers (its three x, y, z components), as many numbers as is its dimensionality. While typical vectors one can imagine in the "real world around us" are 3-dimensional or less, nothing prevents you from thinking of 10-dimensional, 768-dimensional, 1536-dimensional vectors (… or even infinite-dimensional vectors. But I digress).
A vector, in short, is a way to denote a point belonging to a given space. You can picture a vector as an arrow, whose tip is the denoted point. It is an expectation from vector geometry that the "length" (or norm) of a vector be defined regardless which direction it is oriented, i.e. a vector space implies some meaningful notion of "rotation" for its vectors.
Don’t confuse the length with the count of the components (i.e. the dimension, which is always a positive integer).
Take all possible 2-dimensional (x, y) vectors: the points they describe form the whole of a flat plane! Now take only the vectors of length equal to one ("unit vectors"): their points form a circle (of radius one). Likewise, the unit length vectors with dimension three are a sphere in space.
Below, I’ll speak of "spheres" in a broad sense, regardless of the dimension (circles, spheres and "hyperspheres" alike): so, when I say "vectors on a sphere," I actually just mean "vectors of some dimensionality whose length is equal to one."
Of similar and dissimilar vectors
Comparing numbers is easy: 10 is similar to 10.3 and very different from, say, 9979. Just look at (the absolute value of) their difference! What about vectors: how can you say whether two vectors are "similar", or "close", to each other?
It turns out that with vectors there are several ways ("measures") to decide what "close to each other" might mean.
The subtle differences between the available definitions are enough to warrant a deeper investigation... and a dedicated section later in this post!
Even though these definitions differ in their mathematical formulation, they are all ways to quantify, with a number, the degree of similarity between vectors. Conceptually, higher similarity means the vectors are closer to each other, or – equivalently – their distance is lower. This fact holds regardless of the "measure" being adopted.
Here is a brief overview of the measures I will consider (which happen to be the choices available on Cassandra and Astra DB). Choosing to commit to a measure or another is largely based on the nature of the data you want to represent as vectors, and how you do it:
- Euclidean similarity: "how close to each other the tips of the two arrows are"
- Cosine similarity: "by how much are the two arrows pointing to the same direction (regardless of the vectors' lengths)"
- Dot-product similarity: this is the oddball of the bunch. You'll see more about "Dot" later on.
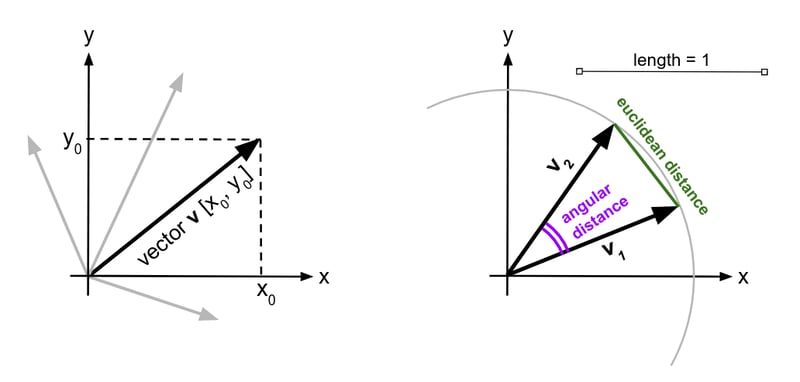
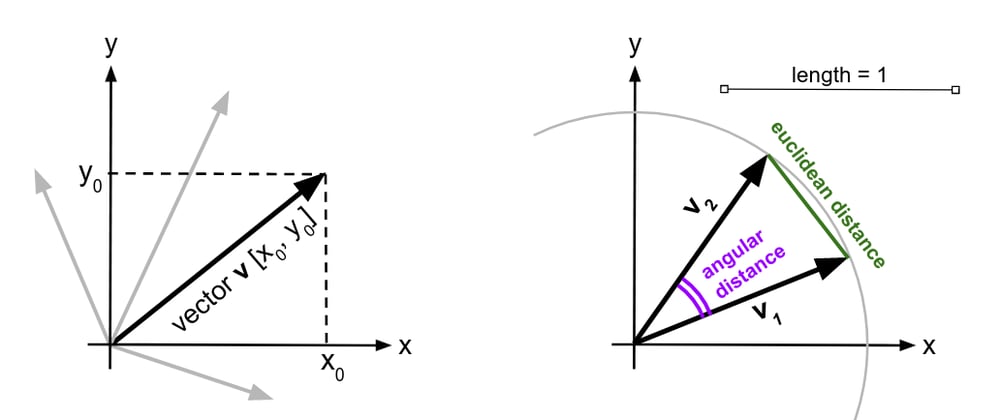
Caption: Vectors in two dimensions, on the whole plane (left) and limited to a circle of radius one (a "two-dimensional sphere"). Vectors can be thought of as lists of numbers, but they are usually represented as arrows anchored at an origin point. The "angular distance" on the right is related to the Cosine similarity between two vectors: smaller angle means higher similarity. Likewise, vectors with a smaller Euclidean distance (pictured) are more similar.
There are a few other definitions of vector similarity available; most are variations of the Euclidean family, but you need not be concerned with them here.
Note that generally one prefers to think in terms of "similarity" rather than "distance," as the former lends itself to fewer mathematical complications and more immediate practical applicability.
Let's get the terms right
In a sense, this article is a mathematical essay in disguise. That means that even if I do my best to keep the number of formulae to a minimum, I still need to use the right concepts precisely and with rigor. For this reason, let's start with a few definitions.
For this series of articles, I will consistently use the following terms:
Dimension or dimensionality: denoted by d, this amounts to how many numbers (components) form the vector, or equivalently the number of independent directions in the vector space. For example, vectors denoting positions on a sheet of paper have d=2, while for locations in the space around you vectors with d=3 are needed. d is much higher than that for most AI-related vector applications. Comparing vectors with different dimensions just makes no sense.
Length or norm: for a vector v, this is denoted by |v|. It is the length of the arrow from tip to tail. One can calculate it as the square root of the sum of the squares of all the components:
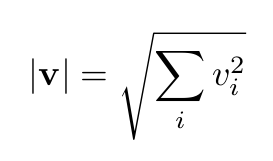
Measure: a mental model of "what it means for vectors to be close/distant." One can consider a Cosine measure, an Euclidean measure, and so on. Choosing a measure does not mean committing to a precise formula just yet.
As mentioned above, I prefer using the notion of "similarity" over that of "distance" where possible. Cassandra and Astra DB never expose anything that is a "distance," only similarities; moreover, not all measures offer a natural and simple-to-understand "distance" to think about.
Similarity: a numeric way to quantify how much two vectors v1 and v2 are close to each other, computed with some formula S(v1, v2). One expects that S(v1, v2) = S(v2, v1); one also requires this quantity to be higher for pairs of vectors that are more similar to each other. It is desirable (and often verified) that this quantity be bound within a known range: for Cassandra and Astra DB, similarities are chosen so as to lie between zero (most dissimilar, or very high-distance, vectors) and one (most similar). As you will see, though, there is a notable exception to this general rule!
Unit sphere: The set of all vectors with unit length (all the vectors v for which |v| = 1). When I say that vectors are "on a sphere", it is implied that they are on the unit sphere. This special (and very common) case unlocks a few nice properties.
For the mathematically inclined, here are the relevant formulae behind the different similarities. In these, xi with i=1,... d denote the components of vector x (i.e. each one of the numbers in the list representing x).

Not every list of numbers is a vector
An implied assumption when thinking of vectors is that rotations in their space should "make sense" (pardon the non-rigorous parlance—you're not reading a linear algebra textbook). This essentially amounts to their components being "of the same kind", and is critical for a proper interpretation of the "similarity" between vectors (whatever its precise definition).
Suppose you associate a list of numbers such as [price, average_rating] to searchable ecommerce items. These are heterogeneous quantities. As a consequence, it is not well defined what we mean by "two items having distance 5 from each other": the lack of a natural way to rotate vectors in this space invalidates the notion of similarity as well. What a downer!
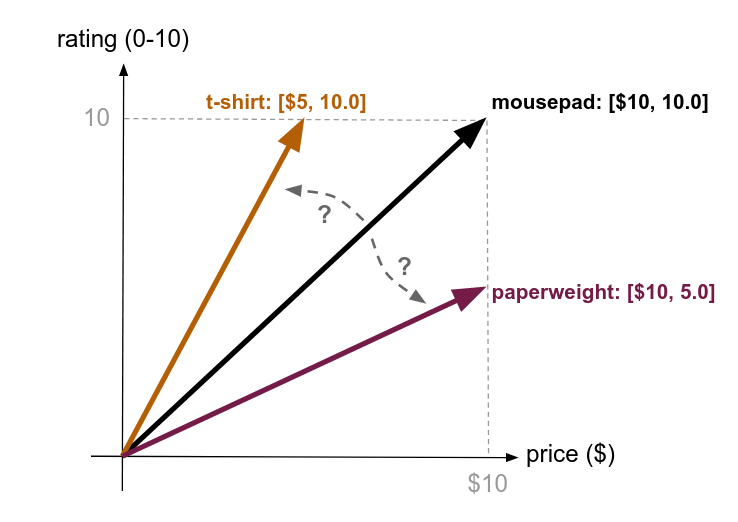
Caption: Which item is "closer" to the mousepad: the t-shirt or the paperweight? Certainly geometry alone cannot easily answer such a question. In other words, what we are saying is that the problem of comparing a distance of $5 on the money axis to a distance of 5 on the rating axis is not just a geometry problem.
A practical rule then is the following: applying vector search methods is a sensible approach, generally, if and only if the dimensions are of the same kind – in other words, if one can think of summing the numbers in the list in a meaningful way.
This is the case, for instance, for a vector expressing a position on a map as [meters_north_of_home, meters_west_of_home], but also – crucially – for the sentence embedding vectors that are being used so fruitfully in the GenAI world nowadays.
There are, indeed, advanced, "non-conventional" cases where one might concoct and use such a pseudo-vector – here's an example.
Coming up next, we’ll explore one of the most important choices one must face when designing a vector-powered application: which similarity measure should be adopted? We briefly covered the Euclidean, Cosine and Dot-product options (their virtues and their differences) but are these similarities so dissimilar after all? Stay tuned to find out – see you next time!





Top comments (0)