The K8ssandra team is happy to announce the release of K8ssandra-operator v1.1. Since February and the first GA release, we have been working hard on making it possible to restore Medusa backups from one cluster to another. Even better, it is now possible to restore a Medusa backup from any Apache Cassandra™ cluster running outside of Kubernetes to K8ssandra.
Let’s dive into the changes remote restore support involves and the other enhancements v1.1 brings to your K8ssandra clusters.
Remote Restore Support
In Medusa, we distinguish two kinds of restores: in-place and remote.
An in-place restore is when you restore a backup on the Cassandra cluster where it was created. This is the simplest case as the token ranges are exactly the same between the source and the target, making the restore operation fairly straightforward. This type of restore has been supported since K8ssandra 1.0.
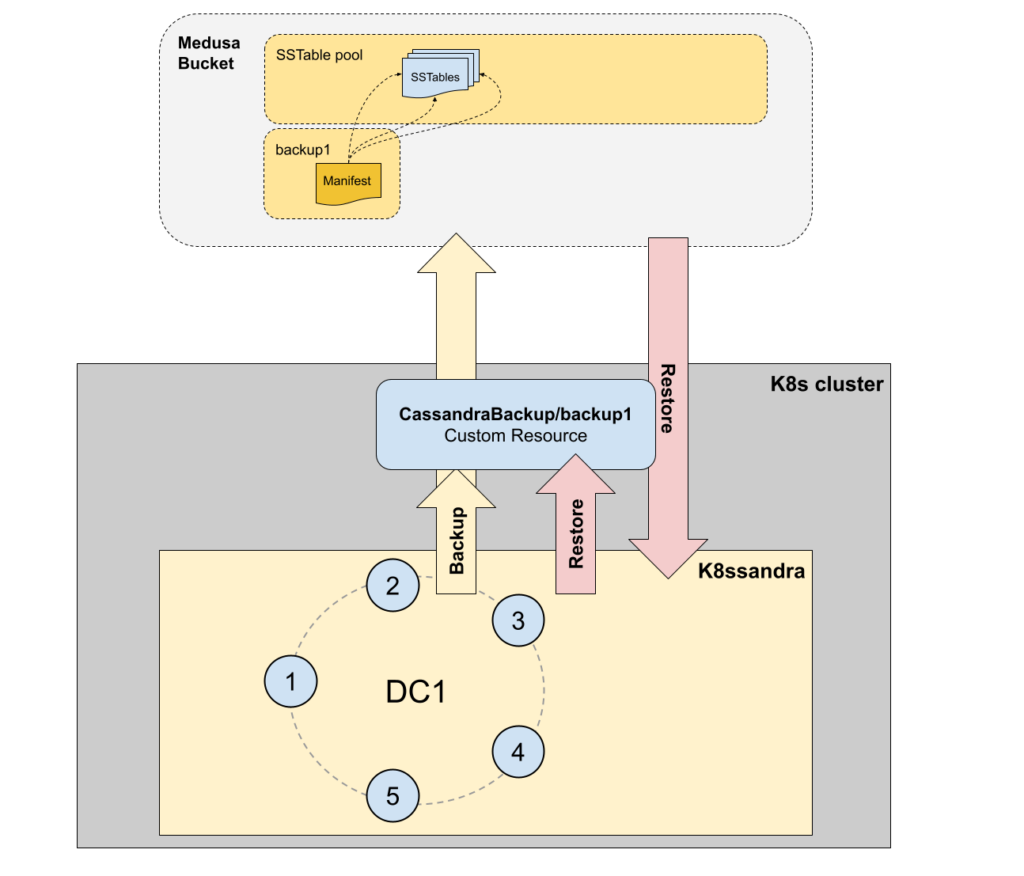
A remote restore is when you restore a backup to a different cluster. That cluster can have a different name, and it most probably has different token ranges if you’re using vnodes.
This is way more complex as the nodes will have to get their token ranges enforced to match the backup cluster, and be re-bootstrapped since you cannot change the tokens of a bootstrapped node.
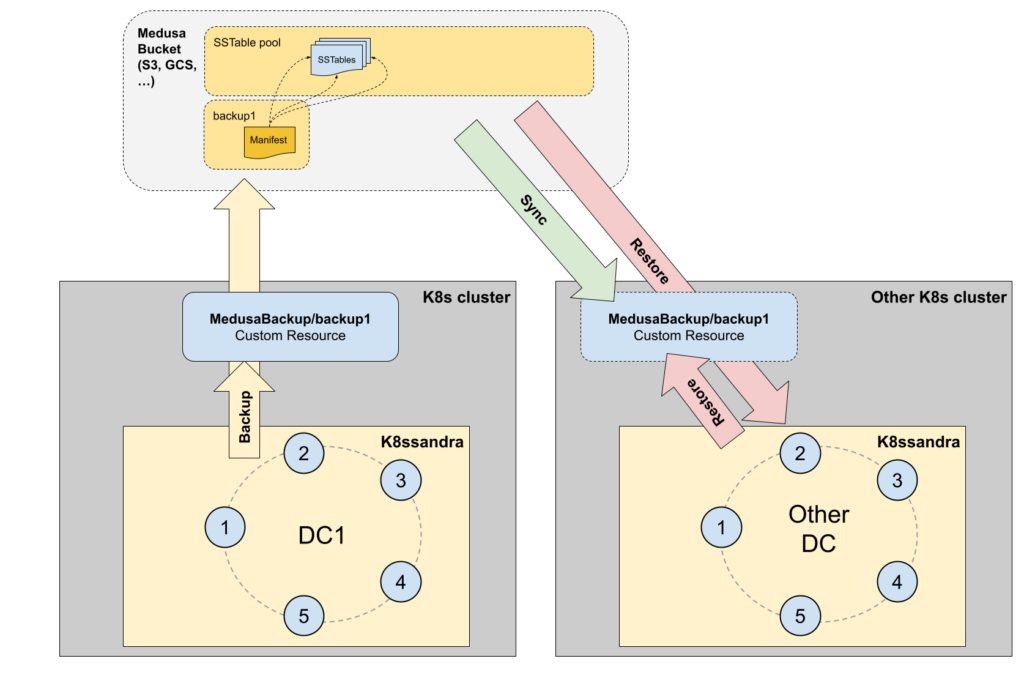
Another missing piece to implement remote restore in K8ssandra was the synchronization of the Medusa storage bucket with the backup custom resource of the Kubernetes cluster.
New Custom Resources
This new design led to the creation of four new CRDs: MedusaBackup, MedusaBackupJob, MedusaRestoreJob and MedusaTask.
Since cass-operator recently introduced CassandraTask objects to orchestrate rebuilds and other maintenance operations, it felt right to harmonize the names of all backup/restore related objects with the “Medusa” prefix instead of the former CassandraBackup and CassandraRestore objects. Those two still exist but are now deprecated, cannot be used for remote restores and will be removed in a later version.
Creating a backup: MedusaBackupJob and MedusaBackup
The MedusaBackup objects materialize a backup as a custom resource but their creation does not trigger the actual backup operation like the former CassandraBackup objects did. Running a backup operation now requires creating a MedusaBackupJob object, which will automatically create a MedusaBackup object upon completion:
apiVersion: medusa.k8ssandra.io/v1alpha1 kind: MedusaBackupJob metadata: name: backup1 spec: cassandraDatacenter: dc1
The MedusaBackup object and the corresponding Medusa backup in the storage backend, will be created with the same name as the MedusaBackupJob. By doing so we’re removing the need to specify a name both in metadata and in the spec of the objects, which was a little redundant.
Restoring a MedusaBackup is done by creating a MedusaRestoreJob object:
apiVersion: medusa.k8ssandra.io/v1alpha1 kind: MedusaRestoreJob metadata: name: restore1 spec: cassandraDatacenter: dc1 backup: backup1
The operator will check that the MedusaBackup custom resource exists before proceeding with the restore operation.
Synchronizing backups between the bucket and k8s: MedusaTask
When restoring a backup to a new cluster, the MedusaBackup object won’t exist locally. MedusaTask custom resources were introduced to perform operations such as purge and sync. Medusa must be configured to use the same storage bucket as the backup cluster, then a sync MedusaTask object needs to be created to create all the missing MedusaBackup objects:
apiVersion: medusa.k8ssandra.io/v1alpha1 kind: MedusaTask metadata: name: medusa-sync1 spec: cassandraDatacenter: dc1 operation: sync
Wait until the status of the MedusaTask object shows a finishTime value:
% kubectl get MedusaTask/medusa-sync1 -o yaml ... status: finishTime: '2022-05-13T12:51:11Z' startTime: '2022-05-13T12:50:31Z' ...
Restoring a backup: MedusaRestoreJob
All the backups that exist in the storage bucket should now be mirrored as MedusaBackup objects, allowing a restore through the creation of a MedusaRestoreJob object:
apiVersion: medusa.k8ssandra.io/v1alpha1 kind: MedusaRestoreJob metadata: name: restore1 spec: cassandraDatacenter: dc1 backup: backup-to-restore-1
From the outside, the restore will be performed as it is with previous versions. There are a few additional steps though:
- A prepare-restore MedusaTask will be created to have Medusa generate a mapping file for each pod so that they know which node they mirror in the backup cluster.
- Upon restart, that file is read by Medusa to trigger the restore appropriately.
- Since the restore is a remote one, the cassandra.yaml file will be modified with the tokens of the mirrored node in the backup cluster.
- cass-operator will orchestrate the startups so that the nodes rebootstrap correctly, seeds first.
The status of the MedusaRestoreJob object will show a finishTime value when the restore operation is finished:
... status: datacenterStopped: '2022-05-13T13:02:34Z' finishTime: '2022-05-13T13:08:49Z' restoreKey: 6af04bc5-cb68-4ce9-b1ca-9a43b46eb74b restorePrepared: true startTime: '2022-05-13T13:02:04Z' ...
Your pods should be up and running shortly after that.
Purging Backups
Purging backups in K8ssandra was no easy task until now. Starting with v1.1, MedusaTask objects expose a purge operation:
apiVersion: medusa.k8ssandra.io/v1alpha1 kind: MedusaTask metadata: name: medusa-purge1 spec: cassandraDatacenter: dc1 operation: purge
The purge will be triggered on all pods and after completion, you will get an update in the status showing how many backups and files were deleted, how much storage space was recovered and the number of files that were protected by their GC grace (10 days by default and configurable in Medusa):
status:
finishTime: '2022-05-13T16:06:34Z'
finished:
- nbBackupsPurged: 1
nbObjectsPurged: 4
podName: testing-dc1-default-sts-0
totalPurgedSize: 228221
- nbBackupsPurged: 1
nbObjectsPurged: 4
podName: testing-dc1-default-sts-1
totalObjectsWithinGcGrace: 32
totalPurgedSize: 237121
- nbBackupsPurged: 1
nbObjectsPurged: 4
podName: testing-dc1-default-sts-2
totalPurgedSize: 226039
startTime: '2022-05-13T16:06:23Z'
A sync operation will be scheduled automatically through a MedusaTask after a purge so that your Kubernetes storage reflects the backups present in the storage bucket.
Medusa CLI now shipped in the image
Medusa wasn’t properly compiled in the Docker image, which required a fairly convoluted command to invoke medusa. Thanks to an external contributor, this is now fixed and all medusa commands can be executed when SSHing into the medusa container:
cassandra@testing-dc1-default-sts-0:~$ medusa list-backups testing-backup2 (started: 2022-05-13 16:03:02, finished: 2022-05-13 16:03:19) testing-backup3 (started: 2022-05-13 16:05:28, finished: 2022-05-13 16:05:44)
This will make it easier to execute commands that are not yet exposed in a cloud native way, such as medusa status or medusa verify, as well as the fairly important medusa delete–backup (don’t forget to perform a sync after this one).
Other enhancements
All JVM options are now exposed in the JvmOptions struct of the K8ssandra cluster CRD. This allowed us to fix some issues with JVM settings that weren’t properly applied on all versions of Cassandra and build an abstraction layer to decorrelate the CRD option names from the cassandra.yaml and jvm*.options ones. As a lot of new settings and renamed ones are shipping in the upcoming Cassandra 4.1, this will make the upgrades way more seamless for K8ssandra ops.
Upgrade Now
We invite all K8ssandra v1.x and K8ssandra-operator users to upgrade to K8ssandra-operator v1.1 (see our installation documentation).
Check our zero downtime migration blog post when upgrading from Apache Cassandra, cass-operator and K8ssandra v1.x clusters.
Let us know what you think of K8ssandra-operator by joining us on the K8ssandra Discord or K8ssandra Forum today. For exclusive posts on all things data, follow DataStax on Medium.