
In a previous post, we discussed the ins and outs of vectors and how to interact with them.
Here, I’ll provide a more detailed account of vector similarities and how they behave. Let's start with the Euclidean and the Cosine similarities.
Let’s say you want to measure how close two points (two vectors) are. How do you proceed? If your plan is to place a ruler between them and, well, measure the distance, then congratulations: you just invented what is called "Euclidean" (or L2) distance. Let's call it δeucl, a number ranging from zero to infinity (you have encountered it already in the introductory table above).
The next step is to make this quantity into a similarity proper: the choice made in Apache Cassandra and in DataStax Astra DB, Seucl = 1/(1+δeucl2), guarantees a quantity in the zero-to-one range and is also computationally not too expensive. Moreover, one gets Seucl=1 for two identical vectors, while very, very far-apart vectors would have a similarity approaching zero. So far for the Euclidean similarity.
Of the (few) other choices, the Cosine similarity is the most common (and is available in Cassandra / Astra DB). The key aspect is that it discards the length part of the vectors and just looks at how well their directions are aligned to each other. Consider the angle formed between the two vectors: when this angle is zero, you have two arrows pointing exactly in the same direction, i.e. two vectors with similarity of one. As the angle increases, the arrows are less and less aligned, and their cosine similarity decreases, down to the extreme case of two perfectly opposed vectors, which corresponds to similarity zero. It takes a moment of thinking to notice that this definition, possibly a bit weird when the vectors may have different norms (i.e. lengths), "feels correct" when all vectors are of unit length.
Important note: rescaling the similarities so that they range between zero and one is a somewhat arbitrary, but practically useful, choice. Elsewhere, you may see a slightly different definition for the cosine similarity, S*cos, chosen instead to range from -1 to +1. There are pros and cons in both choices of S*cos and Scos, and a good suggestion is to always be aware of the specifics of the similarity function your system is using (for more on the subtleties of the scale of similarities, check the last sections of this writeup).
The comfort of the sphere
There should be a saying along the lines of, "On the sphere, life is easy."
The essence of vector search is as follows: given a "query vector," one wants to find, among those stored in the database, the vectors that are most similar to it, sorted by decreasing similarity. Of course, this is based on the similarity measure you choose to adopt! So, what are the changes in the results for different similarities?
You have just seen the Cosine and the Euclidean similarities. There is no doubt they do different things. But here is an important fact: on the sphere, no matter what similarity you use, you get the same top results in the same order.
The reason is perhaps best given with a picture:
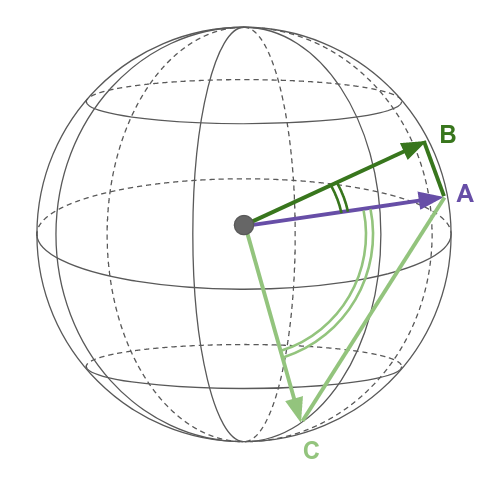
Caption: On the unit sphere, no matter whether using the Euclidean or Cosine similarity, B is more similar to A than to C. In other words, smaller angles subtend shorter segments: angle(AB) < angle(AC) iff AB < AC. (Related: it so happens that most sentence embedding vectors are indeed of unit length, and when they are not, you are probably better off by normalizing the vector to unit length yourself: v ⇒ v/|v|).
Here, then, is the main takeaway for vectors on a sphere: regardless of whether you use the Euclidean or the Cosine similarity, a vector search returns the same top matches, arranged in the same order. The only difference is in the exact values for the similarities. But this is a difference fully under our control: you see, on the sphere it can be proven that there is a mathematically precise relation between the similarities for a given pair of vectors.
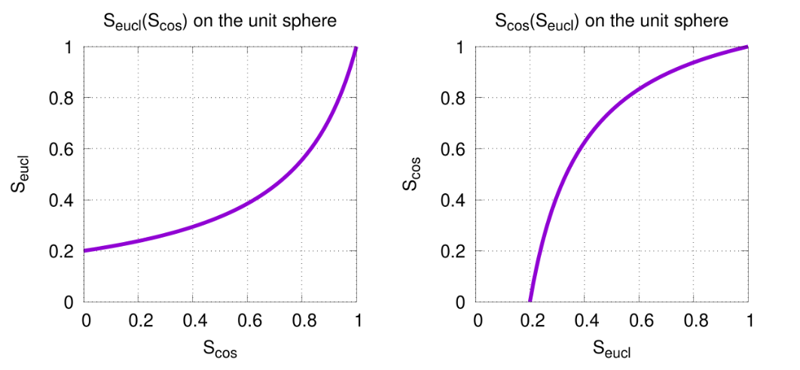
Caption: On the unit sphere, and only in that case, the Cosine and Euclidean similarities can be related to each other directly, without the need for additional information on the vectors. The relations, pictured here, are as follows: Seucl = 1/(5-4Scos) and conversely Scos = (5Seucl-1)/(4Seucl). It is important to notice that these are increasing functions, implying that switching between measures does not alter the "more similar than…" relation. Note also that, on the sphere, the Euclidean similarity has its minimal value at 0.2 (corresponding to the fact that two points on the unit sphere cannot have a distance of more than δeucl,max = 2).
The fact that the transformations between Seucl and Scos are strictly increasing functions is at the heart of the "indifference to the measure used" mentioned above. What about thresholds, for instance if your Cosine-powered search needs to cut away vectors with similarity below a certain Scosmin? You can translate thresholds as you'd do similarities, and run the search with the Euclidean measure provided you translate cuts to Seuclmin = 1/(5-4Scosmin).
So here is another takeaway. When you are on a sphere, there is no substantial difference between the Cosine and Euclidean approaches – you should just pick the less CPU-intensive solution to reap a performance boost. And, as it turns out, the least CPU cycles are spent with ... the Dot-product measure, which you'll examine next!
To summarize:
- There's not much to learn by "experimenting with different indexes" on a sphere
- There's nothing deep to be found in "testing different similarities" on a sphere
Dot-product and the sphere
As we anticipated, Dot-product is the odd one of the bunch. But, to one's relief, on the unit sphere, and only there, its results coincide exactly with the Cosine similarity.
The reason becomes clear by looking at the definitions:

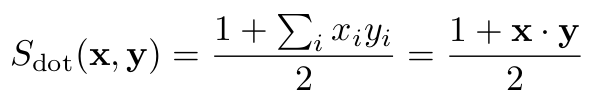
One quickly notices that on the sphere the norms can indeed be omitted, since in that case we have |v|=1 for all vectors v: it follows that Scos = Sdot.
You can then treat the Dot-product similarity as a fully valid substitute for the Cosine similarity, with the advantage that the former requires the least amount of computation. In short, if you can work on the sphere, i.e. if you can ensure all vectors have unit norm, there is no real reason to use anything other than Dot-product in your vector search tables.
Leaving the sphere (i.e. arbitrary vectors)
One lesson so far is that you probably should work on the sphere when it makes sense to do so. If you are working with embedding vectors (whether computed for texts, images or anything really), probably this is the case. Note that you may need to normalize the vectors yourself, since some embedding models may output arbitrary-norm vectors.
There are situations, however, in which the length of vectors also carries important information: an example may be two-dimensional vectors expressing positions on a map for a geo-search-based application. Typically, in these cases you should use the Euclidean measure.
When working with arbitrary vectors, there are real differences between the Cosine and the Euclidean measures: in particular, you cannot just "translate similarities to similarities" without knowing the values of the two vectors themselves.
In other words, you will get different top results when running the same query on the same dataset depending on the measure employed. Let's capture the reason with a drawing:

Caption: Unless your vectors are all of unit length, Euclidean and Cosine similarities tell a different story. Which is the vector closest to A: B or C? (Solution: according to the Euclidean measure, C is most similar to A, while the Cosine similarity has B ranking first.)
Now, with arbitrary vectors, the question whether to use Euclidean or Cosine similarity is more substantial. But, as anticipated earlier, if you choose Cosine you might as well have normalized your vectors at ingestion time to have them on a sphere ... and have in practice used Dot-product! Otherwise, yours is one of those cases for which only the Euclidean choice makes sense: for example, your vectors are the three-dimensional coordinates of inhabited planets and your app helps galactic hitchhikers locate the civilizations closest to them.
That pesky Dot-product
If you are not on the sphere, the Dot-product similarity is not just a "faster Cosine." In this case, the recommendation is not to use it altogether.
The fundamental reason that makes Dot-product stand apart is that this measure, as a candidate way to assess distances, fails our intuition. (This reasoning requires us to speak of "distances," contrary to our earlier resolution – don't worry, we can keep this a very short and tangential digression.)
Here is something we expect from any notion of "distance":
if A is very close to B, and B is very far from C, then A is very far from C
It turns out that the Dot-product admits counter examples that falsify the above intuition (which can be shown to be a consequence of a stricter requirement called "triangle inequality," when taking a particular limiting case). One such counterexample is A = [1, 0]; B = [1, -1/M]; C = [1, M] for sufficiently large values of M.
You can get an intuitive picture of this problem as follows: the Dot-product measure looks at something like "shadows of the vectors as cast with the light source (the query vector) positioned at a certain specific position". Two vectors, whose shadows almost overlap on one wall, might turn out to be in fact not close at all if the light source is moved elsewhere (i.e. searching with a different query vector) and the shadow is cast on another wall.

Caption: With the Dot-product measure, the notion of "similar vectors" depends on what query vector is the comparison anchored to. In the above depiction, the query vector is the light source, which projects objects to one wall or another – with dramatic effects on whether they appear to be close to each other or not. The concept of "being close to each other", therefore, is defined not just by the two items being compared (the rabbit and the pear in the cartoon).
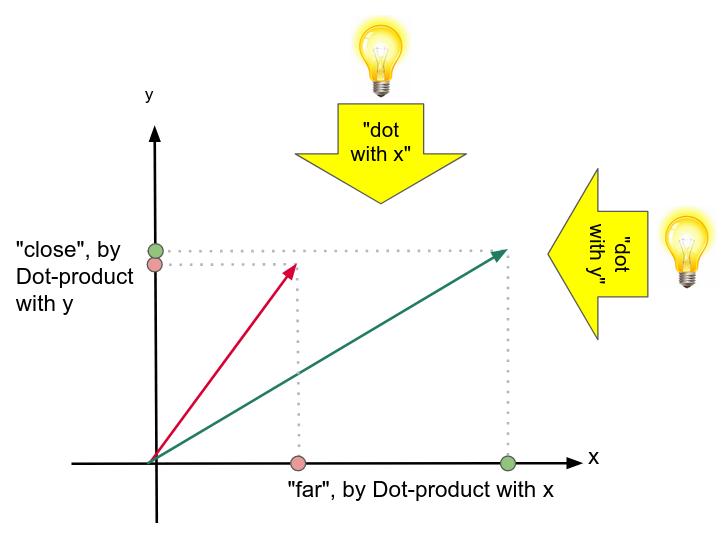
Caption: The quirks of Dot-product, seen in a more formal but otherwise analogous depiction to the "room with a pear and a rabbit" cartoon. If you look at the Dot product with the x axis, i.e. the [1, 0] axis, the two vectors turn out to be much dissimilar – while if you refer them to the [0, 1] query vector they'll look very similar. The notion of "similar vectors" is not an intrinsic property of the vector pair itself.
This oddball character of the Dot-product has three important consequences:
- First, as its expected usage is that of a "faster replacement for Cosine on a sphere", as you step outside of the sphere, your Dot-product similarities are not in the zero-to-one interval anymore. This is a consequence of its mathematical definition:
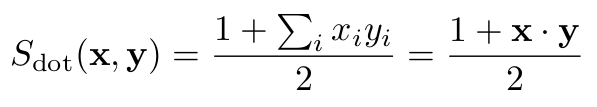
- Second, there is generally no optimization effort aimed at the off-sphere usage of Dot-product. Should you insist on using this measure for arbitrary vectors (and it turns out there are cases where this might have an appeal, if you know what you are doing), the performance implications may be somewhat of an uncharted territory.
- Third, to further elaborate on the previous point, the core idea of the indexes that make vector search so fast rely on precomputed data structures, stored in the index for use by all queries, that provide information on "what is close to what." But here one has a case where closeness changes drastically depending on the query vector being used! So, the effectiveness of such a precomputed structure is greatly hampered and each vector-search query needs much more effort in order to be executed satisfactorily.
Summary table
As we're about to change subject, let's wrap what we've seen so far:
| measure | domain | notes |
|---|---|---|
| Euclidean | sphere (unit-norm vectors) | Consider switching to Cosine or Dot-product (just the numeric similarities change, ordering unchanged) |
| Cosine | sphere (unit-norm vectors) | If you know you're on a sphere, switch to Dot-product (the only change is faster computation) |
| Dot-product | sphere (unit-norm vectors) | The best-performance measure on the sphere |
| Euclidean | arbitrary vectors | Use this if every aspect of the vector (incl. the norm) carries useful information |
| Cosine | arbitrary vectors | Consider normalizing vectors to unit norm at ingestion time and, once on the sphere, switching to Dot-product |
| Dot-product | arbitrary vectors | Probably not what you want (ensure there's a strong reason to fall in this case); performance may be tricky |
The upcoming installment of this series is devoted to the specific choices made in Astra DB and Cassandra with regard to similarities: how to create tables, how to perform queries, what are the associated best practices and pitfalls. Keep reading to find out more – see you next time!





Top comments (1)
True gold content. I appreciate effort you put into dissecting and explaining all the aspects in clear and organized manner.