Building a Wikipedia Chatbot Using Astra DB, LangChain, and Vercel

Carter RabasaHead of Developer Relations

How many times have you asked Google a question, only to get a link to Wikipedia that requires you to click, load the website, and scroll to find the answer?
Wikipedia is a top search result for search engines because it’s a trusted site; people consider the information there to be reliable and authoritative. So why not just go straight to Wikipedia, right? Well, if you tried to go directly to Wikipedia to ask your question, you might get a “does not exist” error along with a list of related pages, and you’d still be hunting for an answer.
We love Wikipedia and everything they’ve done to democratize knowledge, and decided to tackle this problem head on. So we built WikiChat, a way to ask Wikipedia questions and get back natural language answers, using the following tools: Next.js, LangChain, Vercel, OpenAI, Cohere, and DataStax Astra DB.
WikiChat is bootstrapped with the top-1000 most popular Wikipedia pages and then uses Wikipedia’s real-time updates feed to update its store of information. An awesome feature of Astra DB is its ability to concurrently ingest these updates, reindex them, and make them available for users to query without any delay to rebuild indexes.
The WikiChat source code is available on Github. Read on for a deep dive into how we built it.
Architecture
Similar to many retrieval-augmented generation (RAG) applications, we designed this app in two parts: a data ingest script that creates the knowledge base and a web app that provides the conversational experience.
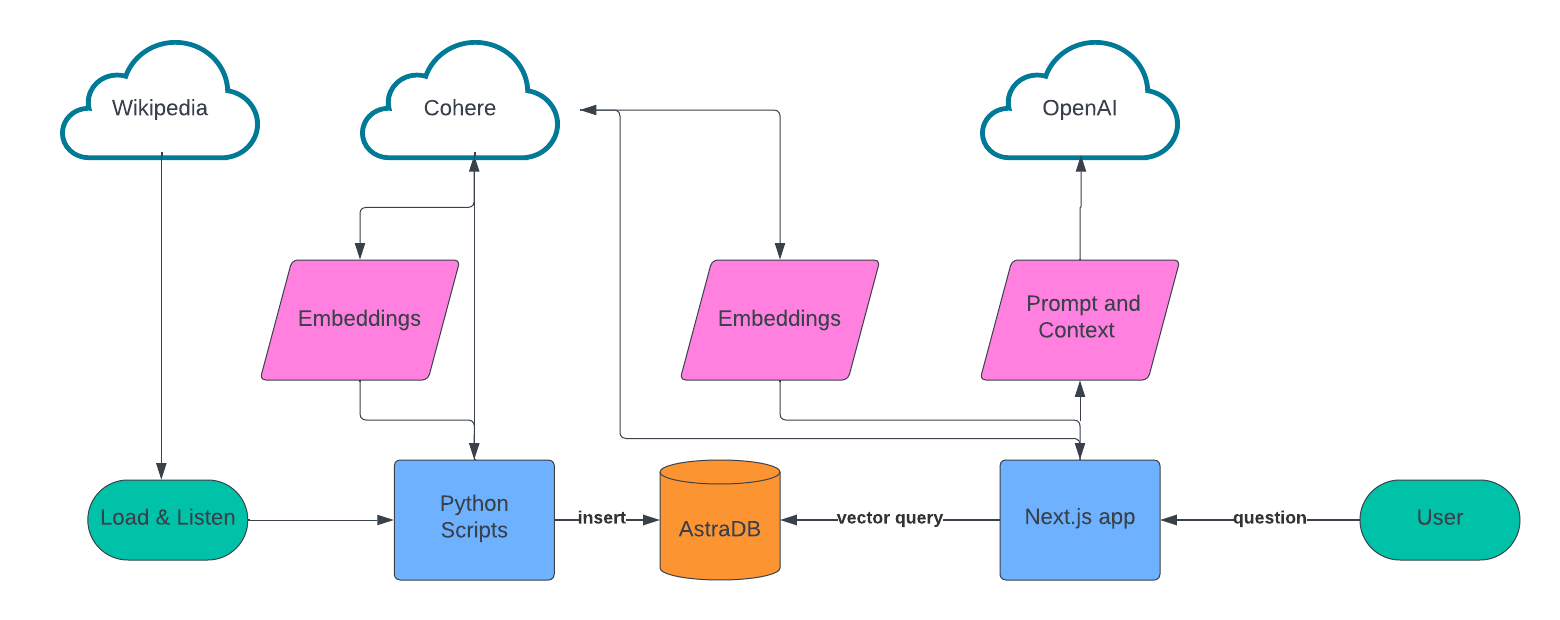
For data ingest, we built a list of sources to scrape, used LangChain to chunk the text data, Cohere to create the embeddings, and then stored all of this in Astra DB.
For the conversational UX, we are building on Next.js, Vercel’s AI library, Cohere, and OpenAI. When a user asks a question, we use Cohere to create the embeddings for that question, query Astra DB using vector search, and then feed those results into OpenAI to create the conversational response to the user.
Setup
To build this application yourself or get our repo up and running, you’ll need a few things:
- A free Astra DB account
- A free Cohere account
- An OpenAI account
After you’ve signed up for Astra DB, you’ll need to create a new vector database. Go ahead and log in to your account.
Next, create a new Serverless Vector database. Give it any name you like and select your preferred Provider and Region.
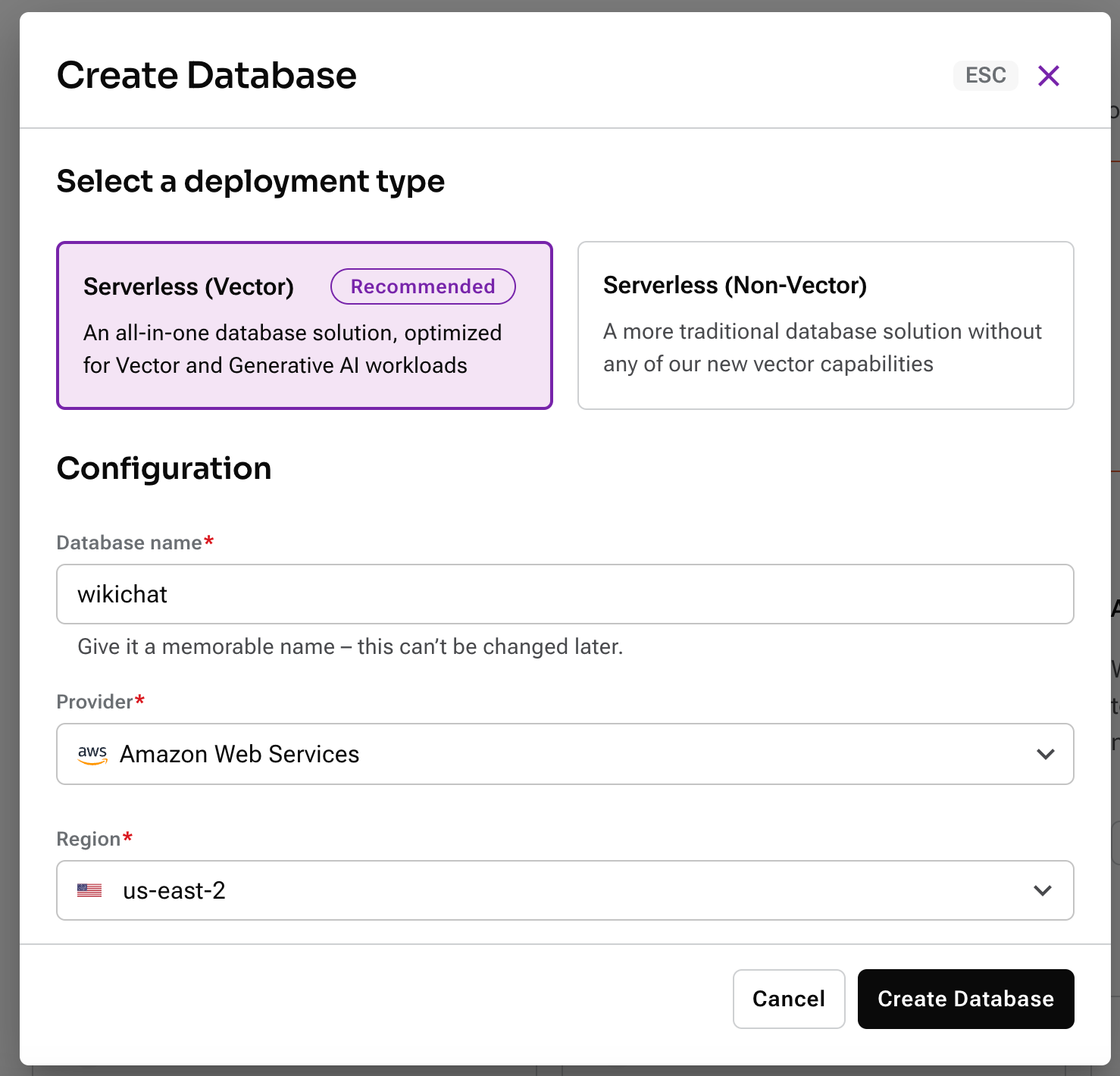
While you’re waiting for the database to provision, copy the .env.example file at the root of the project to .env. You’ll use this to store secret credentials and config information for the APIs that we’ll be using to build this app.
Once your database has been created, create a new application token.
When the modal pops up, click the “copy” button and paste that value into ASTRA_DB_APPLICATION_TOKEN in the .env file. Next, copy your API endpoint:

Paste that value into ASTRA_DB_ENDPOINT in the .env file.
Log in to your Cohere account and go to API keys. You’ll find a trial API key that you can use for development; go ahead and copy that value and store it under the COHERE_API_KEY key.
Finally, log in to your OpenAI account and create a new API key. Store that API key in your .env as OPENAI_API_KEY.
Ok, that’s it—time to write some code!
Ingesting the data
In the scripts directory, you’ll find Python scripts that handle all of the ingest of data for WikiChat. It loads an initial batch of popular Wikipedia articles, then listens for changes to English-language articles using Wikipedia’s published Event Stream.
Note: The event stream includes many forms of updates, such as bots, changes to Talk pages, and even canary events sent to test the system. Regardless of the source, each article passes through five steps to be ingested.
Before we get to the ingestion steps, let's take a quick look at the data we will be storing in Astra using the Data API. The Data API stores data using JSON Documents, grouped together in Collections. By default, every field in the document is indexed and available for querying, including embedding vectors. For the WikiChat application we created three collections:
article_embeddings- Each document stores one chunk of text from an article and an embedding vector created using Cohere. This is the core information that WikiChat needs to answer your chat questions.article_metadata- Each document stores metadata about a single article we have ingested, including the information about the chunks it contained the last time we ingested it.article_suggestions- This collection contains a single document that the script continually updates to keep track of the last 5 processed articles, and for each either the first 5 chunks or the 5 most recently updated.
The scripts/wikichat/database.py file is responsible for initializing the astrapy client library, calling the Data API to create the collections, and creating the client side objects to work with them. The only data modeling we need to do is the Python classes we want to store in each collection. These are defined in the scripts/wikichat/processing/model.py file. The first half of the file defines the classes we use to pass articles through the pipeline discussed below, while the second half defines the classes we want to store in Astra. These classes are all defined as standard Python dataclasses; the classes stored in Astra also use dataclasses-json as the library can serialize data class hierarchies to and from Python dictionaries that are stored in Astra.
For example, the ChunkedArticleMetadataOnly class is stored in the article_metadata collection and is defined as:
@dataclass_json
@dataclass
class ChunkedArticleMetadataOnly:
_id: str
article_metadata: ArticleMetadata
chunks_metadata: dict[str, ChunkMetadata] = field(default_factory=dict)
suggested_question_chunks: list[Chunk] = field(default_factory=list)When we want to store an object of this class (in scripts/wikichat/processing/articles.py/update_article_metadata() ), we use the to_dict() method added by the dataclass_json decoration on the class, which creates a basic Python dictionary for astrapy to store as a JSON document:
METADATA_COLLECTION.find_one_and_replace(
filter={"_id": metadata._id},
replacement=metadata.to_dict(),
options={"upsert": True}
)When we read it back, (in calc_chunk_diff() in the same file), from_dict() is used to rebuild the entire object hierarchy from the stored JSON document:
resp = METADATA_COLLECTION.find_one(filter={"_id": new_metadata._id})
prev_metadata_doc = resp["data"]["document"]
prev_metadata = ChunkedArticleMetadataOnly.from_dict(prev_metadata_doc)With the outline and data access out of the way, it's time to look at how we process each article. Articles are passed through a processing pipeline that’s built using Python Asynchronous I/O. Asynchronous processing is used to deal with both the bursty nature of updates from Wikipedia, and to make sure we keep processing while waiting for the various remote calls the script needs to make. The processing pipeline has five steps:
load_article()retrieves the article from wikipedia.org, and extracts the text from the HTML using Beautiful Soup.chunk_article()breaks the article into chunks that are used to create the embedding vector that describes their semantic meaning. The text is chunked using the RecursiveCharacterTextSplitter from LangChain, and a sha256 hash of the chunk is calculated as a message digest so that chunks can be compared for equality.calc_chunk_diff()first checks Astra to see if we have previous metadata about this article, then creates a "Diff" to describe the current article. The hash of all current chunks is compared to the hashes we know about from the last time we saw the article. A previously unseen article will only contain new chunks of text, while a previously seen one will have a combination of new, deleted, and unchanged chunks.vectorize_diff()calls Cohere to calculate an embedding for the new chunks of text in the article. Calling after calculating the "Diff" means we avoid calculating vectors for chunks of text that have not changed.store_article_diff()updates the Astra to store what we now know about this article; this has three steps:update_article_metadata()updates both the metadata for the article in thearticle_metadatacollection, and thearticle_suggestionscollection to keep track of recent updates so the UI can suggest new questions.insert_vectored_chunks() inserts all the new chunks and their vectors into the article_embeddings collection.delete_vectored_chunks()deletes all the chunks that are no longer present in the updated article.
Building the chatbot user experience
Now that we’ve pre-loaded some popular data from Wikipedia and wired-up real-time updates on content, it’s time to build the chatbot! For this application, we chose to use Next.js, a full-stack React.js web framework. The two most important components of this web application are the web-based chat interface and the service that retrieves answers to a user’s question.
The chat interface is powered by Vercel’s AI npm library. This module helps developers build ChatGPT-like experiences with just a few lines of code. In our application, we’ve implemented this experience in the `app/page.tsx` file, which represents the root of the web application. Here are a few code snippets worth calling out:
"use client";
import { useChat, useCompletion } from 'ai/react';
import { Message } from 'ai';The ”use client”; directive tells Next.js that this module will only run on the client. The import statements make Vercel’s AI library available in our app.
const { append, messages, isLoading, input, handleInputChange, handleSubmit } = useChat();This initializes the useChat React hook, which handles the state and most of the interactive experiences that users have when interacting with the chatbot.
const handleSend = (e) => {
handleSubmit(e, { options: { body: { useRag, llm, similarityMetric}}});
}When a user asks a question, this is the function that handles passing that information to the backend service that figures out what the answer is.
const [suggestions, setSuggestions] = useState<PromptSuggestion[]>([]);
const { complete } = useCompletion({
onFinish: (prompt, completion) => {
const parsed = JSON.parse(completion);
const argsObj = JSON.parse(parsed?.function_call.arguments);
const questions = argsObj.questions;
const questionsArr: PromptSuggestion[] = [];
questions.forEach(q => {
questionsArr.push(q);
});
setSuggestions(questionsArr);
}
});
useEffect(() => {
complete('')
}, []);This initializes the other important hook, which we use to load suggested questions based on the most recently updated pages from Wikipedia that we’ve indexed. The onFinish handler receives a JSON payload from the server which it uses to setSuggestions to be displayed in the UI. Let’s dig into this on the server-side to see how these suggested questions are created.
Pre-populating some suggested questions to get started

As mentioned, when the user first loads WikiChat, it provides some suggested questions which are based on pages from Wikipedia that have been updated recently and been ingested by the app. But how do we go from a recently updated page to a suggested question? Let’s examine /api/completion/route.ts to see what’s happening:
import { AstraDB } from "@datastax/astra-db-ts";
import { OpenAIStream, StreamingTextResponse } from "ai";
import OpenAI from "openai";
import type { ChatCompletionCreateParams } from 'openai/resources/chat';Here, we’re importing the following resources: the Astra DB client, some helpers from Vercel’s AI SDK, the OpenAI client and a helper type that we’ll discuss shortly.
const {
ASTRA_DB_APPLICATION_TOKEN,
ASTRA_DB_ENDPOINT,
ASTRA_DB_SUGGESTIONS_COLLECTION,
OPENAI_API_KEY,
} = process.env;
const astraDb = new AstraDB(ASTRA_DB_APPLICATION_TOKEN, ASTRA_DB_ENDPOINT);
const openai = new OpenAI({
apiKey: OPENAI_API_KEY,
});Next, we initialize the Astra DB and OpenAI clients based on the keys that we configured in our .env file.
const suggestionsCollection = await astraDb.collection(ASTRA_DB_SUGGESTIONS_COLLECTION);
const suggestionsDoc = await suggestionsCollection.findOne(
{
_id: "recent_articles"
},
{
projection: {
"recent_articles.metadata.title" : 1,
"recent_articles.suggested_chunks.content" : 1,
},
});Remember back when we discussed the ingest process and we stored the 5 most recently updated Wikipedia articles in a document in the database? Here is where we query that document using the client’s findOne function. The projection option enables us to tell the client to only return the attributes of the document that we specify.
const docMap = suggestionsDoc.recent_articles.map(article => {
return {
pageTitle: article.metadata.title,
content: article.suggested_chunks.map(chunk => chunk.content)
}
});
docContext = JSON.stringify(docMap);Once we have the document, we use it to create a simple array object of “page title” and “content” pairs that we will pass as context when we make our call to the LLM.
const response = await openai.chat.completions.create({
model: "gpt-3.5-turbo-16k",
stream: true,
temperature: 1.5,
messages: [{
role: "user",
content: `You are an assistant who creates sample questions to ask a chatbot.
Given the context below of the most recently added data to the most popular pages
on Wikipedia come up with 4 suggested questions. Only write no more than one
question per page and keep them to less than 12 words each. Do not label which page
the question is for/from.
START CONTEXT
${docContext}
END CONTEXT
`,
}],
functions
});Now that we have the data (title and content) for the most recently updated Wikipedia pages, you might be wondering how we turn this into suggested questions for our app. Well, when in doubt, ask an LLM to figure it out!
In the call to OpenAI’s chat completion API, we construct a prompt where we ask the LLM to use the data that is passed to build the appropriate questions. We provide instructions on what kind of questions, how long they should be and we set the temperature to 1.5 (values can range from 0 - 2) in order to get more creative responses.
The last parameter of functions allows us to pass in a custom function. In our case we’re using this to define the “shape” of the response we get back from OpenAI so that we can parse it easily and use it to populate the suggested questions in the UI.
const functions: ChatCompletionCreateParams.Function[] = [{
name: 'get_suggestion_and_category',
description: 'Prints a suggested question and the category it belongs to.',
parameters: {
type: 'object',
properties: {
questions: {
type: 'array',
description: 'The suggested questions and their categories.',
items: {
type: 'object',
properties: {
category: {
type: 'string',
enum: ['history', 'science', 'sports', 'technology', 'arts', 'culture',
'geography', 'entertainment', 'politics', 'business', 'health'],
description: 'The category of the suggested question.',
},
question: {
type: 'string',
description: 'The suggested question.',
},
},
},
},
},
required: ['questions'],
},
}]; Buried deep within this payload there are two key values that we’re defining and expecting to get back. The first is category, a string that is one of a handful of predefined values that we use to set the icon in the application UI. The second is question, a string that represents the suggested question to display to the user in the UI.
Using RAG to answer your questions

Now that we’ve explained how suggested questions are built, let’s see what happens when the user asks WikiChat a question. That request is handled by the backend API route defined in /app/api/chat/route.ts and makes extensive use of LangChain’s JS SDK. Let’s break it down and see what’s happening:
import { CohereEmbeddings } from "@langchain/cohere";
import { Document } from "@langchain/core/documents";
import {
RunnableBranch,
RunnableLambda,
RunnableMap,
RunnableSequence
} from "@langchain/core/runnables";
import { StringOutputParser } from "@langchain/core/output_parsers";
import { PromptTemplate } from "langchain/prompts";
import {
AstraDBVectorStore,
AstraLibArgs,
} from "@langchain/community/vectorstores/astradb";
import { ChatOpenAI } from "langchain/chat_models/openai";
import { StreamingTextResponse, Message } from "ai";These imports make the relevant parts of the Langchain JS SDK available to us. You’ll notice that we’re using Langchain’s built-in support for Cohere and OpenAI as LLMs and Astra DB as a vector store.
const questionTemplate = `You are an AI assistant answering questions about anything
from Wikipedia the context will provide you with the most relevant data from wikipedia
including the pages title, url, and page content.
If referencing the text/context refer to it as Wikipedia.
At the end of the response add one markdown link using the format: [Title](URL) and
replace the title and url with the associated title and url of the more relavant page
from the context
This link will not be shown to the user so do not mention it.
The max links you can include is 1, do not provide any other references or annotations.
if the context is empty, answer it to the best of your ability. If you cannot find the
answer user's question in the context, reply with "I'm sorry, I'm only allowed to
answer questions related to the top 1,000 Wikipedia pages".
<context>
{context}
</context>
QUESTION: {question}
`;
const prompt = PromptTemplate.fromTemplate(questionTemplate);The question template is what we use to build a prompt for the LLM that we can inject additional context into in order for it to provide the best possible answer. The instructions are fairly self explanatory, and notice that we instruct it to provide a link to the source page on Wikipedia in markdown format. We’ll take advantage of this later when we’re rendering the answer in the UI.
const {messages, llm } = await req.json();
const previousMessages = messages.slice(0, -1);
const latestMessage = messages[messages?.length - 1]?.content;
const embeddings = new CohereEmbeddings({
apiKey: COHERE_API_KEY,
inputType: "search_query",
model: "embed-english-v3.0",
});
const chatModel = new ChatOpenAI({
temperature: 0.5,
openAIApiKey: OPENAI_API_KEY,
modelName: llm ?? "gpt-4",
streaming: true,
}); Inside of the POST function, we receive values for the chat history (messages) and use those values to define previousMessages and latestMessage. Next, we initialize Cohere and OpenAI for use in LangChain.
const astraConfig: AstraLibArgs = {
token: ASTRA_DB_APPLICATION_TOKEN,
endpoint: ASTRA_DB_ENDPOINT,
collection: “article_embeddings”,
contentKey: “content”
};
const vectorStore = new AstraDBVectorStore(embeddings, astraConfig);
await vectorStore.initialize();
const retriever = vectorStore.asRetriever(10);Now it’s time to configure the Astra DB vector store for LangChain, where we specify our connection credentials, the collection we are querying from and a limit of 10 documents to come back from the DB.
const chain = RunnableSequence.from([
condenseChatBranch,
mapQuestionAndContext,
prompt,
chatModel,
new StringOutputParser(),
]).withConfig({ runName: "chatChain"});
const stream = await chain.stream({
chat_history: formatVercelMessages(previousMessages),
question: latestMessage,
});This is where the LangChain magic happens ✨
First, we create a RunnableSequence by passing in a series of Runnables. All you need to know at this point is that a RunnableSequence starts from the top, executes each Runnable, and passes its output to the next Runnable as input.
After we’ve defined the sequence, we execute it using the chat history and the most recent question. There’s a lot going on in this sequence, so let’s examine each piece.
const hasChatHistoryCheck = RunnableLambda.from(
(input: ChainInut) => input.chat_history.length > 0
);
const chatHistoryQuestionChain = RunnableSequence.from([
{
question: (input: ChainInut) => input.question,
chat_history: (input: ChainInut) => input.chat_history,
},
condenseQuestionPrompt,
chatModel,
new StringOutputParser(),
]).withConfig({ runName: "chatHistoryQuestionChain"});
const noChatHistoryQuestionChain = RunnableLambda.from(
(input: ChainInut) => input.question
).withConfig({ runName: "noChatHistoryQuestionChain"});
const condenseChatBranch = RunnableBranch.from([
[hasChatHistoryCheck, chatHistoryQuestionChain],
noChatHistoryQuestionChain,
]).withConfig({ runName: "condenseChatBranch"}); The first Runnable in the sequence is condenseChatBranch. The purpose of this code is to make WikiChat smart and aware of previously asked questions. Let’s use an illustrative example:
- Question #1: Who is the villain from Star Wars?
- Answer: Darth Vader
- Question #2: Who are his children?
Without knowing what the first question was, the second question makes no sense. So we define a RunnableBranch which functions kind of like an if/else statement. If the Runnable hasChatHistory is true then Langchain will run chatHistoryQuestionChain, or else it will run noChatHistoryChain.
The hasChatHistoryCheck just checks the chat_history input that we defined when we initialized the chain to see if there is a non-empty value.
In the event that this check is true, the chatHistoryQuestionChain Runnable feeds the question and the chat history to the LLM to construct a better question. Let’s look at the condenseQuestionPrompt to see how this works:
const condenseQuestionTemplate = `Given the following chat history and a follow up
question, If the follow up question references previous parts of the chat rephrase the
follow up question to be a standalone question if not use the follow up question as the
standalone question.
<chat_history>
{chat_history}
</chat_history>
Follow Up Question: {question}
Standalone question:`;
const condenseQuestionPrompt = PromptTemplate.fromTemplate(
condenseQuestionTemplate,
);Here, we define a prompt that takes into account our chat history and specifically instructs the LLM to see if the question being asked is a follow-up question. If we use our example from before, the LLM will take the question asked of “Who are his children?” and, looking at the chat history, will rewrite the question as “Who are Darth Vader’s children?” Boom—a smarter chatbot!
Now, if there was no chat history, the noChatHistoryQuestionChain functions as a no-op and just returns the question the user asked unchanged.
const combineDocumentsFn = (docs: Document[]) => {
const serializedDocs = docs.map((doc) => `Title: ${doc.metadata.title}
URL: ${doc.metadata.url}
Content: ${doc.pageContent}`);
return serializedDocs.join("\n\n");
};
const retrieverChain = retriever.pipe(combineDocumentsFn).withConfig({ runName:
"retrieverChain"});
const mapQuestionAndContext = RunnableMap.from({
question: (input: string) => input,
context: retrieverChain
}).withConfig({ runName: "mapQuestionAndContext"});The next in our main sequence is mapQuestionAndContext, which is passed the output from the prior step (the user’s question) and retrieves the closest matching documents from Astra DB and combines them into a string.
This string is then passed to the next step, which is the prompt that we defined earlier. We then pass this fully inflated prompt to the LLM and finally pass the output from the LLM to the LangChain StringParser.
return new StreamingTextResponse(stream);
The last thing to do is return the Langchain stream as a StreamingTextResponse so that the user sees the output of the LLM in real-time as it comes across the wire.
Wrapping it up
Phew, that was a lot of information. Let’s review all the ground that we covered to build an intelligent chat bot that can answer questions about the most popular and recently updated pages on Wikipedia:
- Loading an initial dataset by scraping the 1,000 most popular Wikipedia articles.
- Listening for real-time updates and only processing diffs.
- Intelligently chunking text data using LangChain and generating embeddings using Cohere.
- Storing application and vector data in Astra DB.
- Building a web-based chatbot UX using Vercel’s AI library.
- Performing vector search on Astra DB.
- Generating accurate and context-aware responses using OpenAI.
The current version of WikiChat is deployed to Vercel and you can check it out at: https://wikich.at.
All of the code is open sourced on Github, so please feel free to dig into it and re-use any of the parts that you find useful.
Want to see it in action? Join our livestream on January 24 with our partner LangChain. We’ll build a fully fledged production-ready RAG application using Astra DB, LangChain.JS and Next.js.
If you have any questions about the code, the experience of building on Astra DB, or the new Data API, you can find me on Twitter. Enjoy!
More Technology
View All
How to Build a Crystal Image Search App with Vector Search

Knowledge Graphs for RAG without a GraphDB

